필립슈미트의 에이전틱 패턴에서 영감을 받아 이를 LangGraph로 구현하였습니다.
원글 : (https://www.philschmid.de/agentic-pattern)
모든 코드는 해당 Colab 환경에서 모두 직접 확인해볼 수 있습니다.
https://colab.research.google.com/drive/1JU0BHoCeTg7gJ_OnnvEBcjsw4VpDNuLQ?usp=sharing
개요
에이전트는 작업을 동적으로 계획하고 실행할 수 있다는 특징을 가지고 있습니다. 이때, 단순 혹은 복잡한 작업을 수행하기위해서 외부도구와 메모리를 사용하게 됩니다. 생성형AI 애플리케이션, 특히 LLM을 활용한 애플리케이션을 만들고자할때 가장 고민스러운 부분이 “이 비즈니스 로직을 어떻게 LLM, 에이전트를 활용하여 구현할까?”입니다.
가장 좋은방식은 비즈니스로직을 플로우차트로 구현한다음, 이 구현된 플로우차트에 적절한 디자인 패턴을 활용하면 됩니다. 패턴은 시스템을 생각하고 설계하는 체계적인 방법을 제공하며, 복잡한 애플리케이션을 구축하고 확장하는데 있어서 패턴기반의 모듈실 설계는 수정 및 확장이 더 쉽습니다.
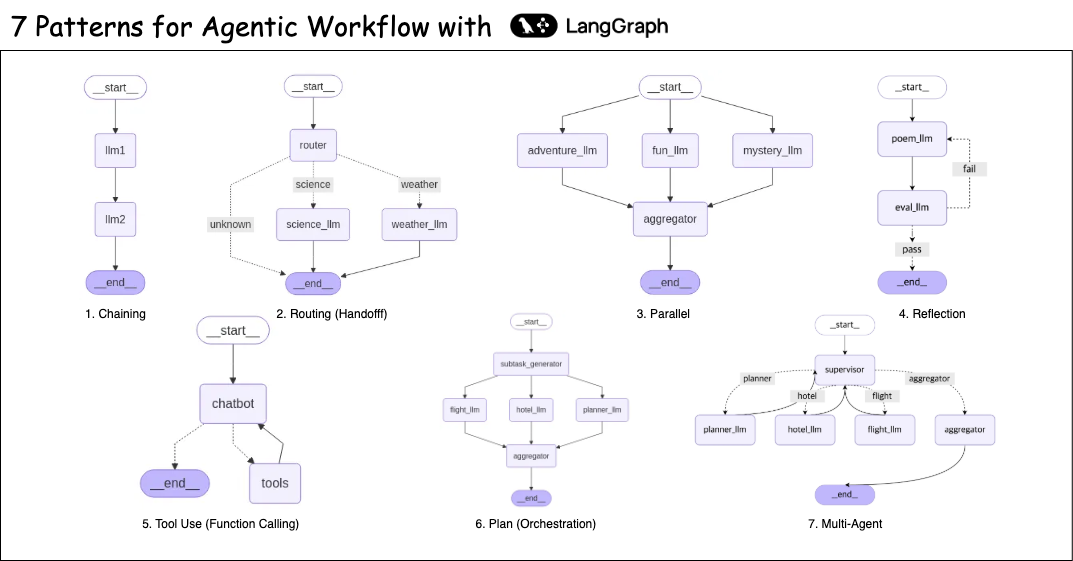
본 블로그에서는 Langchain(Amazon Bedrock을 활용하였습니다) 과 LangGraph를 활용하여 다음 패턴을 작성하는 방법에 대해 알아보겠습니다.
- 프롬프트 체이닝
- 라우팅(핸드오프)
- 병렬화
- 리플렉션 패턴
- 툴 유즈 패턴
- 플랜 패턴 (오케스트레이터와 워커, 수퍼바이저)
- 멀티 에이전트 패턴
핸즈온을 하기에 앞서 준비물
해당 블로그는 Langgraph라는 python 기반의 Agentic Workflow를 작성할 수 있도록 돕는 프레임워크를 사용합니다. 이를 위해서 기본적인 아키텍쳐와 노드를 예시로 작성하였습니다.
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
# Messages have the type "list". The `add_messages` function
# in the annotation defines how this state key should be updated
# (in this case, it appends messages to the list, rather than overwriting them)
messages: Annotated[list, add_messages]
def chatbot(state: State):
return {"messages": [sonnet.invoke(state["messages"])]}
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
except:
# fallback if input() is not available
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
break
자세한 사용법에 대해서는 Langgraph에서 튜토리얼을 제공하므로 이를 참고하세요. (https://langchain-ai.github.io/langgraph/tutorials/)
또한 LangChain이라는 네이티브 API를 추상화하여 제공하는 라이브러리를 사용합니다.
해당 블로그에 작성되는 모든 코드는 다음 코랩 환경에서 시도해볼 수 있습니다.
1. 프롬프트 체이닝
프롬프트 체이닝은 1번 LLM호출에 대한 output을 2번 LLM의 호출에 대한 입력으로 전달되는 형태입니다.
해당 패턴은 작업을 고정된 일련의 단계로 분해하므로, 예측이 가능하고 분해된 단계를 순차적으로 처리할 수 있는 모든 작업에 적합니다.
- 구조화된 문서 생성 - 서로 다른 LLM노드가 개요를 작성하고, 검증하고, 콘텐츠를 작성합니다.
- 다단계 데이터 처리(ETL) - 정보를 추출하고, 변환하고, 요약합니다.
- 큐레이션 기반의 뉴스레터 생성 - 입력된 큐레이션 내용을 가공하고, 뉴스레터를 생성합니다.
다음은 오리지널 텍스트를 한줄로 요약하고 이를 한국어로 변경하는 예 입니다.
 |
 |
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
def llm1(state: State):
original_text = state["messages"][-1].content
llm1_input = f"""
Summarize the following text in one sentence: {original_text}
"""
return {"messages": [sonnet.invoke(llm1_input)]}
def llm2(state: State):
summary = state["messages"][-1].content
llm2_input = f"""
Translate the following summary into Korean, only return the translation, no other text: {summary}
"""
return {"messages": [sonnet.invoke(llm2_input)]}
graph_builder = StateGraph(State)
graph_builder.add_node("llm1", llm1)
graph_builder.add_node("llm2", llm2)
graph_builder.add_edge(START, "llm1")
graph_builder.add_edge("llm1", "llm2")
graph_builder.add_edge("llm2", END)
graph = graph_builder.compile()
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
pass
- llm1은 요약을 진행하는 노드로써, 주어진 메세지에 대해 한줄 요약을 작성합니다.
- 작성된 요약은 llm2 노드의 입력으로 사용되어 한국어로 번역됩니다.

2. 라우팅 (핸드오프)
라우팅은 LLM이 사용자의 쿼리를 입력받아 적합한 다운스트림 작업으로 전달하는데 사용됩니다. 이 패턴은 Adaptive RAG구성에 필수적으로 사용됩니다. (사용자의 쿼리에 따라서 다른 Datasource를 활용하는 방법)
이는 단순히 데이터 소스의 구분에만 사용되는것은 아니며, 분류된 작업에 대해 더 작은 모델을 사용하여 효율성을 높이고 비용을 절감한다던지, 아니면 전문화된 프롬프트나 모델을 적용하는데에도 활용할 수 있습니다.
사용사례)
- 고객 지원 시스템 - 사용자의 쿼리를 분석하여 비용문의 / 기술문의로 나누어 상담원에게 문의를 전달합니다.
- 계층형 LLM - 간단한 질문은 빠르고 저렴한 모델(haiku)로 라우팅하고, 복잡한 질문은 성능이 좋은모델(sonnet)으로 라우팅합니다.
라우팅의 경우 “structured output”과 관계가있습니다. structured output은 llm의 최종 답변(generation)에 대해서 구조화된 output을 생성하도록 하며, 특정 형식이나 자료형으로 출력하도록 구성할 수도 있습니다.
다음은, 사용자의 쿼리를 기반으로 weather / science / unknown 으로 Structured Ouput을 구성하여 라우팅을 하는 예제입니다. langchain에서는 .with_structured_output() 메서드를 활용합니다.
 |
 |
from typing import Annotated, Optional, Literal
from typing_extensions import TypedDict
from pydantic import BaseModel, Field
import enum
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
category: Optional[str]
class Category(enum.Enum):
WEATHER = "weather"
SCIENCE = "science"
UNKNOWN = "unknown"
class Decision(BaseModel):
"""사용자 쿼리를 카테고리화 하세요."""
category: Category = Field(description="쿼리를 카테고리화 하세요. WEATHER / SCIENCE / UNKNOWN 중에 하나로 구분하세요.")
def categorize_function(state: State) -> Literal["weatcher", "science", "unknown"]:
cat = state["category"].lower()
if cat == "weather":
return "weather"
elif cat == "science":
return "science"
else:
return "unknown"
def router(state: State):
original_text = state["messages"]
router_input = f"""
Analyze the user query below and determine its category.
Categories:
- weather: For questions about weather conditions.
- science: For questions about science.
- unknown: If the category is unclear.
Query: {original_text}
"""
structured_llm = sonnet.with_structured_output(Decision)
structured_response = structured_llm.invoke(router_input)
category = structured_response.category.value
print(category)
return {"category": category, "messages": state["messages"]}
def weather_llm(state: State):
messages = state["messages"]
weather_input = f"""
Provide a brief weather forecast for the location mentioned in: '{messages}'
"""
return {"messages": [sonnet.invoke(weather_input)]}
def science_llm(state: State):
messages = state["messages"]
return {"messages": [sonnet.invoke(messages)]}
graph_builder = StateGraph(State)
graph_builder.add_node("router", router)
graph_builder.add_node("weather_llm", weather_llm)
graph_builder.add_node("science_llm", science_llm)
graph_builder.add_edge(START, "router")
graph_builder.add_conditional_edges(
"router",
categorize_function,
{
"weather": "weather_llm",
"science": "science_llm",
"unknown": END
}
)
graph_builder.add_edge("weather_llm", END)
graph_builder.add_edge("science_llm", END)
graph = graph_builder.compile()
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
pass
- LLM라우터는 사용자의 쿼리를 받아서 science, weather, unkown으로 구분합니다.
- 구분된 정보에 따라 각기 다른 node로 라우트되며, unknown의 경우 응답을 종료합니다.

3. 병렬화
작업이 동시에 처리되어져야하는 하위 작업으로 나뉘고, 이를 병합하여 사용해야할 때가 있습니다. 이패턴에 동시성을 사용하게되며, 여러 노드로 병렬로 전송됩니다. 모든 노드에서 태스크가 수행되면 이를 집계합니다. 해당 패턴은 하위작업이 서로 의존성을 가지지 않는경우에 유용하며, 결론적으로 직렬처리하는 워크플로우 대비 지연시간을 크게 줄일 수 있습니다.
사용사례)
- 쿼리 분해를 활용한 RAG - 쿼리를 다수의 하위 쿼리로 나눠서 병렬검색을 실행, 이를 종합합니다.
- 페르소나 - 여러 LLM에게 각기 다른 관점의 페르소나를 부여하고, 동일한 질문에 대한 종합적인 답변을 수집합니다.
langgraph에서는 해당 부분에 대해서 fan-out 및 fan-in 메커니즘을 활용하여 구현되며, 기본적으로 병렬 실행을 지원하기 때문에 앞서 설명한 것과 같이 전체 그래프 작업의 속도를 크게 향상시킬 수 있습니다.
다만 유의할점은, langgraph에서는 분기된 노드에서 하나라도 예외가 발생한다면, 전체스텝(super-step)이 오류처리가되어 스테이트가 업데이트되지 않습니다.
 |
 |
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
def adventure_llm(state: State):
message = state["messages"][-1].content
adventure_input = f"""
Write a short, adventurous story idea about {message}.
"""
return {"messages": [sonnet.invoke(adventure_input)]}
def fun_llm(state: State):
message = state["messages"][-1].content
fun_input = f"""
Write a short, funny story idea about {message}.
"""
return {"messages": [sonnet.invoke(fun_input)]}
def mystery_llm(state: State):
message = state["messages"][-1].content
mystery_input = f"""
Write a short, mysterious story idea about {message}
"""
return {"messages": [sonnet.invoke(mystery_input)]}
def aggreator(state: State):
messages = state["messages"]
aggregation = f"""
Combine the following three story ideas into a single, cohesive summary paragraph:{messages}
"""
return {"messages": [sonnet.invoke(aggregation)]}
graph_builder = StateGraph(State)
graph_builder.add_node("adventure_llm", adventure_llm)
graph_builder.add_node("fun_llm", fun_llm)
graph_builder.add_node("mystery_llm", mystery_llm)
graph_builder.add_node("aggregator", aggreator)
graph_builder.add_edge(START, "adventure_llm")
graph_builder.add_edge(START, "fun_llm")
graph_builder.add_edge(START, "mystery_llm")
graph_builder.add_edge("adventure_llm", "aggregator")
graph_builder.add_edge("fun_llm", "aggregator")
graph_builder.add_edge("mystery_llm", "aggregator")
graph_builder.add_edge("aggregator", END)
graph = graph_builder.compile()
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
pass

4. 리플렉션 패턴
리플렉션(반사? 반영? 번역하기 애매한 단어)패턴은 출력에 대한 평가를 진행하고, 그에대한 피드백을 활용하여 응답을 반복적으로 개선하는 패턴입니다. 일반적으로 평가패턴이라고 부르기도 합니다. 여기에는 LLM을 활용한 평가 노드가 포함되어있으며, 출력의 요구사항이나 질을 평가하여 비교하고, 새로생성할지 아니면 패스할지를 결정하게 됩니다.
사용사례)
- 코드생성 - 코드를 작성하고, 실행하고, 오류메세지를 분석하여 최종적으로 버그없는 코드를 생성합니다.
- 글쓰기 - 초안을 작성하여 전달하면, 최종으로 원하는 아웃풋 형태로 출력할때까지 반복합니다.
 |
 |
from typing import Annotated, Optional, Literal
from typing_extensions import TypedDict
from pydantic import BaseModel, Field
import enum
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
evaluation: Optional[str]
feedback: Optional[str]
reasoning: Optional[str]
current_poem: Optional[str]
class EvaluationStatus(enum.Enum):
PASS = "pass"
FAIL = "fail"
class Evaluation(BaseModel):
"""사용자 쿼리를 카테고리화 하세요."""
evaluation: EvaluationStatus = Field(description="평가 결과를 제공하세요. PASS / FAIL 로만 제공하세요.")
feedback: str = Field(description="평가 피드백을 제공하세요.")
reasoning: str = Field(description="평가 이유를 제공하세요.")
def evaluation_function(state: State) -> Literal["pass", "fail"]:
evaluation = state["evaluation"].lower()
if evaluation == "pass":
return "pass"
elif evaluation == "fail":
return "fail"
else:
return "fail"
def eval_llm(state: State):
print("eval llm")
messages = state["messages"]
current_poem = state.get("current_poem", "")
eval_input = f"""
Critique the following poem. Does it rhyme well? Is it exactly four lines?
Is it creative? Respond with PASS or FAIL and provide feedback.
Poem:
{current_poem}
"""
structured_llm = sonnet.with_structured_output(Evaluation)
structured_response = structured_llm.invoke(eval_input)
evaluation = structured_response.evaluation.value
feedback = structured_response.feedback
reasoning = structured_response.reasoning
print(evaluation)
print("feedback: ", feedback)
print("reasoning: ", reasoning)
return {
"messages": state["messages"],
"evaluation": evaluation,
"feedback": feedback,
"reasoning": reasoning
}
def poem_llm(state: State):
messages = state["messages"]
feedback = state.get("feedback", "")
reasoning = state.get("reasoning", "")
current_poem = state.get("current_poem", "")
poem_input = ""
if current_poem == "" :
print("no_poem")
poem_input = f"""
Write a short, four-line poem about {messages[-1].content}.
"""
else:
print("has_poem")
poem_input = f"""
Write a short, four-line poem about {current_poem}.
"""
if feedback:
poem_input += f"""
Feedback: {feedback}
"""
if reasoning:
poem_input += f"""
Reasoning: {reasoning}
"""
print("poem_input : ", poem_input)
response_poem = sonnet.invoke(poem_input)
print("gen poem : ", response_poem.content)
return {
"messages": [response_poem],
"current_poem": response_poem.content
}
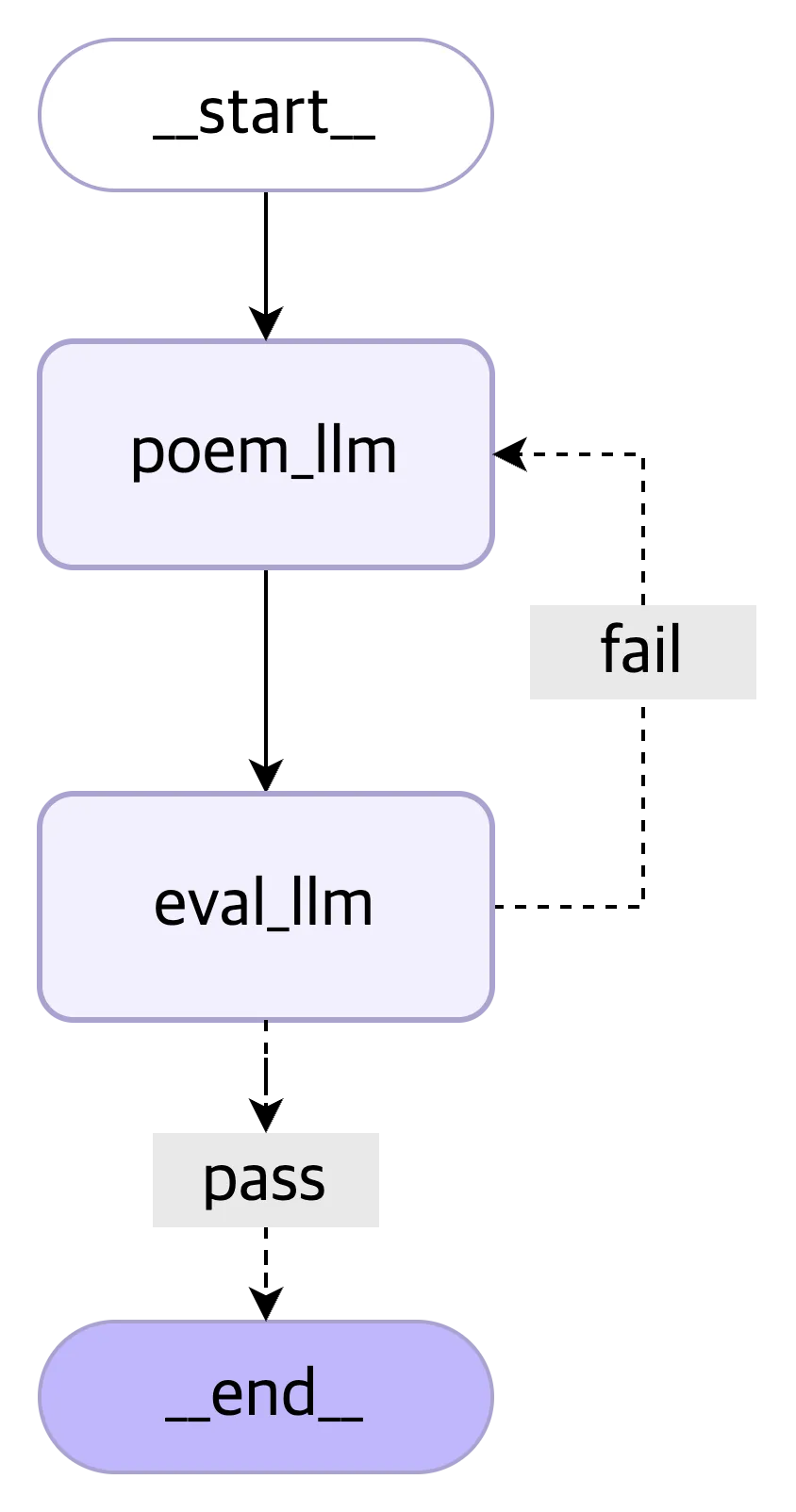
graph_builder = StateGraph(State)
graph_builder.add_node("poem_llm", poem_llm)
graph_builder.add_node("eval_llm", eval_llm)
graph_builder.add_edge(START, "poem_llm")
graph_builder.add_edge("poem_llm", "eval_llm")
graph_builder.add_conditional_edges(
"eval_llm",
evaluation_function,
{
"pass": END,
"fail": "poem_llm",
}
)
graph = graph_builder.compile()
- 사용자의 쿼리를 받아서 시 작성 노드에서 시를 생성합니다.
- 생성된 시를 평가 노드에서 평가합니다. 이때 pass면 종료, fail이면 다시 생성합니다.
- 다시 생성하는경우 feedback과 reasoning을 함께 전달합니다.

5. 툴 유즈 패턴
외부 함수나 API를 호출하여 real world와 상호작용하는 로직이 필요할때 적용할 수 있는 패턴입니다. 이 패턴은 함수 호출 (Function Calling), 툴 유즈 (Tool Use), 더 나아가서 넓은 개념으로 보면 최근 Claude에서 발표한 MCP(Model Context Protocol)등도 이 툴 유즈 패턴을 사용한다고 이야기 할 수 있을정도로 중요한 패턴입니다.
LLM은 사용자의 쿼리를 기반으로 어떤툴을 사용할지를 결정하여(이 또한 LLM모델이 결정합니다.) 실제로 툴을 실행, 결과를 얻고 최종적으로 LLM이 결과를 얻어 사용자에게 최종적으로 응답을 제공하는 플로우를 가집니다.
LangGraph에서는 이를 Tool Node로써 구현할 수 있어 간단하지만, 직접 구현하고자 할때에는 모델이 툴을 사용할 수 있다고 판단하여 tool call을 포함한 응답(json)을 생성하는것 과정의 전부이며, 이 응답을 가지고 툴을 실행하는것과, 툴의 실행 결과를 다시 LLM이 반영하여 응답(generation)을 생성하는 부분은 수동적으로 구현해야합니다.
사용사례)
- 캘린더 API를 활용한 약속 예약
- RAG에 대한 벡터 데이터베이스 검색 (이때 Modular RAG라고도 칭합니다)
- 코드의 실행
 |
 |
from typing import Annotated, List, Dict
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_core.messages import AIMessage
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode, tools_condition
@tool
def get_current_temperature(query: str) -> Dict:
"""get temperature"""
return {"temperature": "15", "unit": "Celsius"}
tools = [get_current_temperature]
tool_node = ToolNode(tools)
class State(TypedDict):
messages: Annotated[list, add_messages]
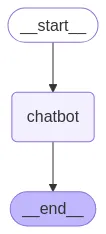
def chatbot(state: State):
model_with_tools = sonnet.bind_tools(tools)
return {"messages": [model_with_tools.invoke(state["messages"])]}
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_node("tools", tool_node)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_conditional_edges("chatbot", tools_condition)
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
pass
- 사용자의 쿼리를 받아서 chatbot노드로 전달됩니다.
- chatbot노드는 사용자의 쿼리를 분석, 이때 사용가능한 툴이 있다면 툴을 호출합니다.
- 툴(여기서는 현재 기온을 가져오는 툴, 실제로는 기상 API등과 연동되어야 함) 실행후 결과를 전달합니다.
- 전달받은 결과를 LLM이 종합하여 사용자에게 최종 응답으로 제공합니다

6. 플랜 패턴 (오케스트레이션, 워커)
플랜패턴은 LLM이 복잡한 작업을 하위 작업으로 분할하고 전문적인 하위 에이전트에 하위작업을 위임하는 패턴입니다. 1차적으로 사용자의 쿼리에 대한 플랜을 작성하고, 이 플랜에는 어떤 에이전트로 위임할지에 대한 내용을 함께 기록합니다. 이때 종속성등을 고려하여 병렬로 실행될 수 있으며 최종적으로 수집기에서 결과를 수집하여 최종 응답(generation)을 생성하게 됩니다.
이전의 라우팅과 비슷하지만 이 경우에는 다음 노드로의 직접적인 라우트를 진행하는 것이 아닌 계획만을 생성하며, 이 생성된 계획을 바탕으로 하위작업이 실행되는것은 오히려 위에서 설명한 “병렬화”에 해당됩니다.
사용사례)
- 복잡한 소프트웨어 개발 - 기능 계획, 코딩, 테스트, 문서화의 하위태스크로 세분화
- 복잡한 사용자 요청 - 여행 계획 플래너 등
 |
 |
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class Roles(enum.Enum):
PLANNER = "planner"
HOTEL = "hotel"
FLIGHT = "flight"
class Subtask(BaseModel):
description: str
assignee: Roles = Field(description="어떤 워커가 해당 일을 처리해야하나요? PLANNER / HOTEL / FLIGHT 중에 하나로 구분하세요.")
class Tasks(BaseModel):
goal: str
steps: List[Subtask]
class State(TypedDict):
messages: Annotated[list, add_messages]
tasks: Tasks
def subtask_generator(state: State):
try:
original_text = state["messages"]
subtask_input = f"""
주어진 태스크를 바탕으로 서브태스크를 생성하세요.
각각의 태스크들은 어떤태스크를 수행해야하는지와 일을 처리하는 담당자를 지정해야합니다.
태스크: {original_text}
"""
structured_llm = sonnet.with_structured_output(Tasks)
structured_response = structured_llm.invoke(subtask_input)
tasks = structured_response
print("tasks: ", tasks)
print(type(tasks))
return {"messages": [state["messages"][-1]], "tasks": tasks}
except Exception as e:
print(e)
return {"messages": "task generation failed"}
def planner_llm(state: State):
subtasks = state["tasks"].steps
goal = state["tasks"].goal
planner_tasks = [task.description for task in subtasks if task.assignee == Roles.PLANNER]
print("my plans:", planner_tasks)
planner_input = f"""
당신은 계획을 새우는 계획 에이전트입니다.
주어진 목표와 태스크의 설명을 참고하여 태스크를 수행하세요.
한글로 제공하세요
목표: {goal}
태스크(들)설명: {str(planner_tasks)}
"""
response = sonnet.invoke(planner_input)
print(response)
return {"messages": [response]}
def flight_llm(state: State):
subtasks = state["tasks"].steps
goal = state["tasks"].goal
flight_tasks = [task.description for task in subtasks if task.assignee == Roles.FLIGHT]
print("my plans:", flight_tasks)
flight_input = f"""
당신은 항공권을 예약하는 예약 에이전트입니다.
현재 항공권 관련하여 수행할 수 있는 툴이나 외부 API가 없으니 더미데이터를 생성하세요.
주어진 목표와 태스크의 설명을 참고하여 태스크를 수행하세요.
한글로 제공하세요
목표: {goal}
태스크(들)설명: {str(flight_tasks)}
"""
response = sonnet.invoke(flight_input)
print(response)
return {"messages": [response]}
def hotel_llm(state: State):
subtasks = state["tasks"].steps
goal = state["tasks"].goal
hotel_tasks = [task.description for task in subtasks if task.assignee == Roles.HOTEL]
print("my plans:", hotel_tasks)
hotel_input = f"""
당신은 호텔을 예약하는 예약 에이전트입니다.
현재 호텔 부킹 관련하여 수행할 수 있는 툴이나 외부 API가 없으니 더미데이터를 생성하세요.
주어진 목표와 태스크의 설명을 참고하여 태스크를 수행하세요.
한글로 제공하세요
목표: {goal}
태스크(들)설명: {str(hotel_tasks)}
"""
response = sonnet.invoke(hotel_input)
print(response)
return {"messages": [response]}
def aggreator(state: State):
messages = state["messages"]
aggregation = f"""
당신은 주어진 정보를 바탕으로 최종 정보를 수집 및 정제하여 하나의 플랜을 작성하는 에이전트입니다.
주어진 내용들을 바탕으로 하나의 플랜을 작성하세요.
내용들: {messages}
"""
return {"messages": [sonnet.invoke(aggregation)], "tasks": state["tasks"]}
graph_builder = StateGraph(State)
graph_builder.add_node("subtask_generator", subtask_generator)
graph_builder.add_node("planner_llm", planner_llm)
graph_builder.add_node("hotel_llm", hotel_llm)
graph_builder.add_node("flight_llm", flight_llm)
graph_builder.add_node("aggregator", aggreator)
graph_builder.add_edge(START, "subtask_generator")
graph_builder.add_edge("subtask_generator", "planner_llm")
graph_builder.add_edge("subtask_generator", "hotel_llm")
graph_builder.add_edge("subtask_generator", "flight_llm")
graph_builder.add_edge("planner_llm", "aggregator")
graph_builder.add_edge("hotel_llm", "aggregator")
graph_builder.add_edge("flight_llm", "aggregator")
graph_builder.add_edge("aggregator", END)
graph = graph_builder.compile()
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception as e:
print(e)
- 사용자의 쿼리를 바탕으로 서브태스크를 나눕니다.
- 이 태스크는 담당자 정보(planner, hotel, flight)와 태스크에 대한 description을 함께 담고있습니다.
- 이 태스크를 여러 에이전트로 fan-out 합니다.
- 태스크를 전달받은 에이전트는 본인과 담당자정보가 일치하는경우, 해당 태스크를 진행합니다.
- 최종적으로 aggregator가 하위태스크 수행 결과를 바탕으로 한개의 플랜을 작성합니다.




7. 멀티 에이전트 패턴
특정 페르소나 또는 전문지식(RAG가 포함된 에이전트)을 가진 에이전트가 공동의 목표를 달성하려는 경우 사용하는 패턴입니다. 이 에이전트들은 서로 상호작용하고 협업하게됩니다.
멀티에이전트 패턴에서 가장 중요한것은, 블랙박스 구조에서 발생된 대화들의 흐름이 정확히 의도한 에이전트로 넘어갈 수 있느냐를 고려해야합니다. 이를 위해서 Supervisor, Coordinator라고 불리는 PM역할을 하는 에이전트를 활용하여 흐름을 조절하고 평가하기도 합니다.
멀티에이전트의 경우 Depth가 깊어지면 깊어질수록 명확한 태스크를 수행할 수 있는 Team(Cluster)로 운영이 되어야, 태스크가 올바른 에이전트에 의해 수행될 수 있습니다.
사용사례)
- 브레인스토밍 시뮬레이션
- 가상실험이나 행위자를 대표하는 에이전트를 사용한 시뮬레이션
기존의 패턴들과 다른점이 있다면,
- 수퍼바이저가 다음 node로 라우팅하는것은 라우팅 패턴과 유사하지만 다음 Node의 결과물을 다시 수퍼바이저가 받아서 처리하게 됨.
- 여러 태스크를 여러 노드에서 처리한다는 내용은 병렬(팬아웃)과 유사하지만 하나의 태스크를 수행하고 다른 태스크를 수행하는 순차적인 단계를 따르므로 요청을 처리하는 에이전트가 다른 에이전트의 결과물을 참조할 수 있음.
등등이 있습니다.
 |
 |
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class Nodes(enum.Enum):
PLANNER = "planner"
HOTEL = "hotel"
FLIGHT = "flight"
AGGREGATOR = "aggregator"
class State(TypedDict):
messages: Annotated[list, add_messages]
next_node: Nodes
class Decision(BaseModel):
"""사용자 쿼리를 기반으로 계획을 세우고 다음 처리할 노드를 결정하세요."""
next_node: Nodes = Field(description="처리할 노드를 결정하세요. PLANNER / HOTEL / FLIGHT / AGGREGATOR 중에 하나로 결정하세요.")
def decision_function(state: State) -> Literal["planner", "hotel", "flight", "aggregator"]:
decision = state["next_node"].lower()
if decision == "planner":
return "planner"
elif decision == "hotel":
return "hotel"
elif decision == "flight":
return "flight"
elif decision == "aggregator":
return "aggregator"
else:
return "aggregator"
def supervisor(state: State):
original_text = state["messages"]
supervisor_input = f"""
사용자의 요청을 기반으로 계획을 세우고 각각의 에이전트로 라우트하세요.
사용가능한 에이전트
1. 계획 에이전트
2. 항공권 예약 에이전트
3. 호텔 예약 에이전트
4. 집계 에이전트
먼저 계획을 세워야합니다.
세워진 계획을 바탕으로 항공권과 호텔을 예약합니다.
항공권과 호텔 예약을 마쳐야 집계 에이전트를 사용할 수 있습니다.
최종적으로 요청을 처리하였다고 판단하였으면 집계 에이전트로 라우트합니다.
사용자 요청: {original_text}
"""
structured_llm = sonnet.with_structured_output(Decision)
structured_response = structured_llm.invoke(supervisor_input)
next = structured_response.next_node.value
print(next)
return {"next_node": next, "messages": state["messages"]}
def planner_llm(state: State):
messages = state["messages"]
planner_input = f"""
당신은 계획을 세워 제공하는 계획 에이전트입니다.
한글로 제공하세요.
사용자에게 되묻지 마세요.
히스토리: {messages}
"""
response = sonnet.invoke(planner_input)
return {"messages": [response]}
def flight_llm(state: State):
messages = state["messages"]
flight_input = f"""
당신은 항공권을 예약하는 예약 에이전트입니다.
현재 항공권 관련하여 수행할 수 있는 툴이나 외부 API가 없으니 더미데이터를 생성하세요.
사용자에게 되묻지 마세요. 항상 최적의 옵션 3개를 제시합니다.
히스토리: {messages}
"""
response = sonnet.invoke(flight_input)
return {"messages": [response]}
def hotel_llm(state: State):
messages = state["messages"]
hotel_input = f"""
당신은 호텔을 예약하는 예약 에이전트입니다.
현재 호텔 부킹 관련하여 수행할 수 있는 툴이나 외부 API가 없으니 더미데이터를 생성하세요.
사용자에게 되묻지 마세요. 항상 최적의 옵션 3개를 제시합니다.
히스토리: {messages}
"""
response = sonnet.invoke(hotel_input)
return {"messages": [response]}
def aggregator(state: State):
messages = state["messages"]
aggregation = f"""
당신은 주어진 정보를 바탕으로 최종 정보를 수집 및 정제하여 하나의 플랜을 작성하는 에이전트입니다.
주어진 내용들을 바탕으로 하나의 플랜을 작성하세요.
주어진 호텔과 항공권 옵션을 종합하여 최적의 플랜을 작성하세요.
내용들: {messages}
"""
response = sonnet.invoke(aggregation)
return {"messages": [response]}
graph_builder = StateGraph(State)
graph_builder.add_node("supervisor", supervisor)
graph_builder.add_node("planner_llm", planner_llm)
graph_builder.add_node("hotel_llm", hotel_llm)
graph_builder.add_node("flight_llm", flight_llm)
graph_builder.add_node("aggregator", aggregator)
graph_builder.add_edge(START, "supervisor")
graph_builder.add_conditional_edges(
"supervisor",
decision_function,
{
"planner": "planner_llm",
"hotel": "hotel_llm",
"flight": "flight_llm",
"aggregator": "aggregator",
}
)
graph_builder.add_edge("planner_llm", "supervisor")
graph_builder.add_edge("hotel_llm", "supervisor")
graph_builder.add_edge("flight_llm", "supervisor")
graph_builder.add_edge("aggregator", END)
graph = graph_builder.compile()



정리
지금까지 에이전트를 구성하는 7가지의 에이전틱 패턴에 대해 알아보았습니다. 해당 패턴을 활용하면 더 쉽게 동적인 에이전트 구축이 가능할것이며, 여러가지 패턴이 결합된 패턴은 더욱 강력한 에이전트를 구축하는데 도움이 될것입니다.
LLM 애플리케이션 구축을 완료하였다면, 이에 대한 벤치마킹을 진행하여 새로운 전략을 수립하고, 패턴을 적용하고 리팩토링하는 과정을 계속해서 시도해야합니다. 해당 글이 LangGrpah를 활용하여 에이전트 구축을 목표로하는 모든 이들에게 도움이 되었으면 합니다.
'LLM' 카테고리의 다른 글
| RAG 구축에 있어서 고려해야 할 점들 (0) | 2025.05.07 |
|---|---|
| LLM 프로젝트에 적절한 모델 선택하기 (2) | 2025.04.04 |

